As continuation of big data query system blog, i want to share more techniques for building Analytics engine.
Take a problem where you have to build system that will be used for analyzing customer data at scale.
What options are available to solve this problem ?
- Spark SQL by removing Job start overhead.
Analytics query generate different type of load, it only needs few columns from the whole set and executes some aggregate function over it, so column based database will make good choice for analytics query.
Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
So using Spark data can converted to parquet and then Spark SQL can be used on top of it to answer analytics query.
To put all in context convert HDFS data to parquet(i.e column store), have a micro services that will open Sparksession , pin data in memory and keep spark session open forever just like database pool connection.
Connection pool is more than decade old trick and it can be used for spark session to build analytics engine.
High level diagram on how this will look like

Spark Session is thread safe, so no need to add any locks/synchronization.
Depending on use case single or multiple spark context can be created in single JVM.
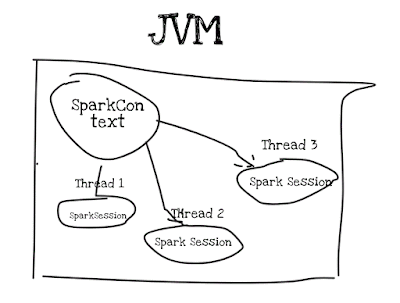 Spark 2.X has simple API to create singleton instance for SparkContext and handles thread based SparkSession also.
Spark 2.X has simple API to create singleton instance for SparkContext and handles thread based SparkSession also.
Code snippet for creation spark session
Caution
All this works fine if you have micro service running on single machine but if this micro service is load balanced then each instance will have one context.
If single spark context requests for thousands of cores then some strategy is required to load balancing Spark context creation. This is same as database pool issue, you can only request for resource that is physically available.
Another thing to remember that now driver is running in web container so allocate proper memory to process so that web server does not blow up with out of memory error.
I have create micro services application using Spring boot and it is hosting Spark Session session via Rest API.
This code has 2 types of query
- Single query per http thread
- Multiple query per http thread. This model is very powerful and can be used for answering complex query.
Code is available on github @ sparkmicroservices
Take a problem where you have to build system that will be used for analyzing customer data at scale.
What options are available to solve this problem ?
- Load the data in your favorite database and have right indexes.
This works when data is small, when i say small less then 1TB or even less.
- other option is to use something like elastic search
Elastic search works but it comes up with overhead of managing another cluster and shipping data to elastic search
-use spark SQL or presto
Using these for interactive query is tricky because of minimum overhead that is required to execute query can be more than latency required for query which could be 1 or 2 sec.
Using these for interactive query is tricky because of minimum overhead that is required to execute query can be more than latency required for query which could be 1 or 2 sec.
-use distributed In-Memory database.
This looks good option but it also has some issues like many solution is proprietary and open source one will have overhead similar to Elastic Search.
This looks good option but it also has some issues like many solution is proprietary and open source one will have overhead similar to Elastic Search.
- Spark SQL by removing Job start overhead.
I will deep dive in to this option. Spark has become number one choice for build ETL pipeline because of simplicity and big community support and Spark SQL can connect to any data source ( JDBC,Hive ,ORC, JSON, Avro etc).
Analytics query generate different type of load, it only needs few columns from the whole set and executes some aggregate function over it, so column based database will make good choice for analytics query.
Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
So using Spark data can converted to parquet and then Spark SQL can be used on top of it to answer analytics query.
To put all in context convert HDFS data to parquet(i.e column store), have a micro services that will open Sparksession , pin data in memory and keep spark session open forever just like database pool connection.
Connection pool is more than decade old trick and it can be used for spark session to build analytics engine.
High level diagram on how this will look like

Spark Session is thread safe, so no need to add any locks/synchronization.
Depending on use case single or multiple spark context can be created in single JVM.

Code snippet for creation spark session
Caution
All this works fine if you have micro service running on single machine but if this micro service is load balanced then each instance will have one context.
If single spark context requests for thousands of cores then some strategy is required to load balancing Spark context creation. This is same as database pool issue, you can only request for resource that is physically available.
Another thing to remember that now driver is running in web container so allocate proper memory to process so that web server does not blow up with out of memory error.
This code has 2 types of query
- Single query per http thread
- Multiple query per http thread. This model is very powerful and can be used for answering complex query.
Code is available on github @ sparkmicroservices
Thanks for posting such a great article.you done a great job.
ReplyDeleteMicroservices training in Hyderabad
I have some wonderful microservices interview questions right here
ReplyDeleteGreat Article. Thanks for sharing info.
ReplyDeleteDigital Marketing Course in Hyderabad
Digital Marketing Training in Hyderabad
AWS Training in Hyderabad
Workday Training in Hyderabad
Salesforce Training in Hyderabad
SAP FICO Training in Hyderabad
SAP ABAP Training in Hyderabad
SAP HANA Training in Hyderabad
Nice and good article. It is very useful for me to learn and understand easily. Thanks for sharing your valuable information and time. Please keep updating big data online training
ReplyDeleteI like your post very much. It is very much useful for my research. I hope you to share more info about this. Keep posting Apache Spark Training
ReplyDeleteThanks for sharing the informative post.
ReplyDeleteMachine Learning training in Pallikranai Chennai
Pytorch training in Pallikaranai chennai
Data science training in Pallikaranai
Python Training in Pallikaranai chennai
Deep learning with Pytorch training in Pallikaranai chennai
Bigdata training in Pallikaranai chennai
Mongodb Nosql training in Pallikaranai chennai
Spark with ML training in Pallikaranai chennai
Data science Python training in Pallikaranai
Bigdata Spark training in Pallikaranai chennai
This comment has been removed by the author.
ReplyDeleteYou have leads in hand, your job being a digital marketer is done. Many business owners are able to increase sales and their brand recognition easily with the help of digital marketing on completing our Digital Marketing Course in Hyderabad. In 2021, after the pandemic, businesses are investing more in digital marketing. You could see a huge decline in Traditional marketing efforts. That is truly a positive sign. You master Digital Marketing and you would prosper.
ReplyDeleteOur Affiliate Marketing course in Hyderabad will train you on successful marketing strategies that will help you earn money from different affiliate networks, we will demonstrate how to sign-up for an affiliate program and get approved from them. You will learn amazing new ways to generate traffic to your website. Converting the traffic to sales is very important for which we will guide you to create a winning landing page.
ReplyDeletejava online course
ReplyDeletesalesforce online course
hadoop online course
Data Science online course
linux online course
etl testing online course
Data Science Course in Hyderabad
ReplyDeleteBecome a Data Science Expert with us. we provide classroom training on IBM Certified Data Science at Hyderabad for the individuals who believe hand-held training. We teach as per the Indian Standard Time (IST) with In-depth practical Knowledge on each topic in classroom training, 80 – 90 Hrs of Real-time practical training classes. There are different slots available on weekends or weekdays according to your choices.
Do check our blog MBA in Artificial Intelligence if anyone having a keen interest in Artificial Intelligence.Also check Other courses below.Online MBA in Data Science
ReplyDeleteOnline MBA in Business Intelligence
Get trained on data science course in hyderabad by real-time industry experts and excel your career with Data Science training by Technologyforall. #1 online training institute for Data Science.
ReplyDeleteBecome a career-ready expert in the field of Python by getting enrolled for the advanced Python Course in Hyderabad from the hands of domain experts at AI Patasala.
ReplyDeleteHere is the best music to calm and relax your mind
ReplyDelete1. best relaxing music
2. best Depp sleep music
3. best meditation music
4. best calm music
5. best deep focus music
Get the best Data Science career opportunities by enrolling in AI Patasala Training Institutes Advanced Certified Data Science Course in Hyderabad program. Top-notch industry trainers deliver this with IIT & IIM specialization.
ReplyDeletewill omit your great writing due to this problem.
ReplyDeletedata science training india
data science course hyderabad online
smm panel
ReplyDeletesmm panel
İSİLANLARİBLOG.COM
İNSTAGRAM TAKİPÇİ SATIN AL
Hırdavatçı
https://www.beyazesyateknikservisi.com.tr
SERVİS
tiktok jeton hilesi
Hi Admin, I hope you are fine. I'm one of the biggest fans, I like to read your blogs and I've also shared your blogs with my family members and friends. I hope in future you'll publish more blogs like your old ones. Please accept my thanks on my behalf and from my family and friends.
ReplyDeleteFaisal Town Phase 2
Multi Gardens Phase 2
7 Wonders City Multan
D1 Capital Park City
Capital Smart City
Lahore Smart City
Faisal Town Phase 2
Multi Gardens Phase 2
Blue World City
Silver City Islamabad
Capital Valley Islamabad
Skip Hire Near Me
Mini Skip Hire
2 Yard Skip
4 Yard Skip
6 Yard Skip
8 Yard Skip
Skip Hire Covered Locations
Skip Hire FAQs
Skip Hire Nottingham
Skip Hire Sheffield
Midi Skip Hire Prices
Builders Skip Hire Prices
Maxi Skip Hire Prices
RORO Skip Hire Prices
Fitness Health Hub
Good content. You write beautiful things.
ReplyDeletemrbahis
sportsbet
korsan taksi
sportsbet
hacklink
mrbahis
vbet
hacklink
vbet
It is very useful information at my studies time, i really very impressed very well articles and worth information, i can remember more days that articles.software development company in chennai. Thanks for sharing this information for us.
ReplyDeleteThis post is on your page i will follow your new content.
ReplyDeletecasino siteleri
mrbahis.co
sportsbet
sportsbet giriş
betgaranti.online
mrbahis
casino siteleri
sportsbetgiris.net
sportsbet
This post is on your page i will follow your new content.
ReplyDeletesportsbet giriş
mrbahis
sportsbet
mrbahis giriş
sportsbetgiris.net
casino siteleri
betgaranti.online
mrbahis.co
casino siteleri
I will provide monthly off page SEO backlinks service with white hat link building
ReplyDeleteI will do on page SEO optimization of wordpress with yoast
I will create manually social bookmarking submissions with high da backlinks
I will do optimize wordpress onpage SEO and fix all issues
I will build manually high da social media profiles backlinks
I will set up rank math SEO with 90 score
I will write and publish guest posts on 60 da websites with dofollow link
Latest Cheap Products
What Time Does Doordash Pay on Monday
Sharing Is Caring
How Much Do Amish Charge To Build A House
Why I Quit F45
How Much Does Christopher Hopkins Charge
Thank you for sharing this valuable information with us.
ReplyDeleteJava full-stack course in Hyderabad
The good post ever
ReplyDeleteJava full-stack training in Hyderabad
Thanks for sharing information with us.
ReplyDeleteDigital Marketing Course in Warangal
Java Full Stack Web Developer Course in Warangal
ewfdrwefedsrgfgh
ReplyDeleteشركة تنظيف واجهات زجاج بالاحساء
Spark Microservices offers powerful solutions that enhance performance and scalability. Ideal for businesses seeking a reliable Queue Management System Dubai, it ensures smooth operations and improved customer experience across service points.
ReplyDeleteGreat content! For detailed learning, check out the Spring Boot with Microservices Online Training in Hyderabad. Highly recommended!
ReplyDeleteThank you for sharing this valuable information. It provides great insights for anyone looking for a reliable career training institute in Mylapore. This resource is especially helpful for students and professionals who want to upgrade their skills and explore better career opportunities.
ReplyDelete