Why distributed context ?
Nowadays, modern applications are designed to be distributed across multiple data centers and regions, leveraging diverse technology stacks. As a result, a typical application architecture may span multiple geographical locations and incorporate various technologies, such as microservices, containers, and server less computing, to meet the complex demands of modern businesses. Application stack might look something like this. |
| Application Stack |
In distributed systems, several challenges arise when it comes to maintaining certain aspects such as global state, telemetry recording, long-duration workflow pipeline checkpointing, and feature flags. These challenges are critical to ensuring the reliability, scalability, and fault tolerance of the system.
One of the primary challenges is managing global state, which refers to the data that needs to be shared and synchronized across multiple instances of the application. This can be a complex task, especially in highly distributed environments, where consistency and concurrency control are crucial.
Another key challenge is recording telemetry, which involves collecting, analyzing, and visualizing data about the system's performance, health, and usage. This helps teams monitor and troubleshoot the system, identify bottlenecks, and optimize its overall efficiency.
In addition, keeping track of long-duration workflow pipelines is essential for ensuring that complex tasks are completed reliably and efficiently. This requires checkpointing and resuming workflows from a particular point in the event of failures or other disruptions.
Finally, managing feature flags, which enable the selective enabling or disabling of certain features in the system, is critical for rapid iteration and experimentation. However, managing feature flags across multiple instances of the application can be challenging, as teams need to ensure that the correct flag configuration is propagated to all instances.
What is solution ?
Several solutions exist to tackle these challenges, such as distributed caching, message-oriented middleware, or specialized tools like Zookeeper for managing state. While these solutions can be effective, they often come with the complexity of managing a sophisticated infrastructure. Additionally, implementing a complex infrastructure for a relatively small use case can lead to more issues than solutions.
To address these challenges, OpenTelemetry offers a novel approach called "context and propagation" that operates at the transport layer. The idea behind this approach is to provide a simple and unified way to propagate information across different components of the distributed system.
Inspired by OpenTelemetry's context and propagation, I would like to introduce an idea that could help address these challenges more effectively. This approach involves utilizing a lightweight middleware layer that sits between the different components of the distributed system. The middleware layer would be responsible for managing the state, telemetry, and feature flags, and would provide a simple and standardized API for the application components to interact with.
By using this approach, teams can simplify the management of complex infrastructure while ensuring that their distributed system remains reliable, scalable, and fault-tolerant. Additionally, this approach could help teams experiment with new features and iterate quickly without compromising on the overall performance and stability of the system.
How does context API look ?
The proposed Context API would have several key features to help manage the state, telemetry, and feature flags of a distributed system more effectively. Some of these features include:
Context Name: This feature would enable the association of a user-friendly name with all the state, telemetry, and feature flags in the system. This name can be used to index and query the information easily.
Time to Live: Some context information is short-lived and should be automatically managed by the underlying implementation. This feature would enable the setting of a time to live for the context information, allowing for automatic expiration and cleanup when no longer needed.
Abstract Data Types: The Context API would support abstract data types such as counters, maps, and sets, allowing for flexible and efficient management of the state, telemetry, and feature flags.
Durability: The context information would be durable, meaning it would survive application restarts and remain available for a longer duration, enabling teams to understand the behavior of the distributed system over time.
By incorporating these features, the proposed Context API would provide a lightweight and standardized way to manage the complex state, telemetry, and feature flags of a distributed system, enabling teams to focus on building reliable and scalable applications without the burden of managing a complex infrastructure.
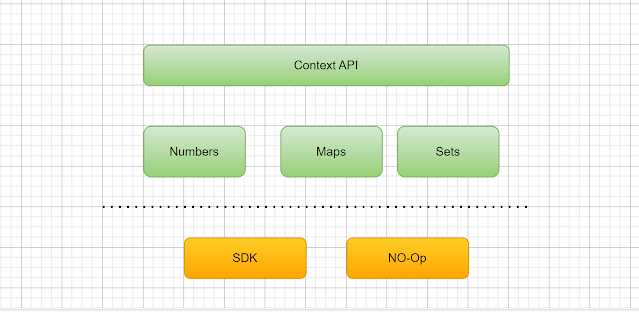 |
| API -> Implementation |
One of the key benefits of designing a system with a clear separation between the API and its implementation is the flexibility it offers. This approach allows teams to easily swap out and upgrade different components of the system without impacting the overall functionality of the API.
Moreover, a clear separation between the API and implementation enables the support of heterogeneous ecosystems, where different components of the system may use different technology stacks or operate in different environments. This allows teams to leverage the strengths of each technology stack and environment, without compromising the overall functionality and interoperability of the system.
In summary, a clear separation between the API and implementation provides teams with flexibility, interoperability, modularity, and maintainability, allowing them to build complex and reliable systems that can support the needs of diverse and dynamic ecosystems.
What operations are supported on Abstract data type
Let's take a closer look at the sample API and the operations it supports. One of the benefits of the proposed Context API is its ability to support a wide range of use cases, and new abstract data types (ADTs) can be added to address more advanced scenarios.
At its core, the Context API provides a simple and standardized way to manage state, telemetry, and feature flags in a distributed system.
The Context API can be extended with new ADTs to support more advanced use cases. For example, a new ADT could be added to support distributed locks, allowing different components of the system to coordinate access to a shared resource. Another ADT could be added to support distributed queues, enabling components to communicate asynchronously in a reliable and scalable manner.

A sample implementation that leverages the concepts discussed above is available at https://github.com/ashkrit/corejava/tree/master/playground/src/main/java/context. This implementation showcases how the proposed Context API can be used to manage state, telemetry, and feature flags in a distributed system.
The sample implementation uses an H2 database for the persistence of state, and this database is abstracted through the ContextProviderClient.java interface. This abstraction enables the use of any backend system to store states, providing flexibility and adaptability.
One of the key challenges of the Context API is state replication in a distributed system. To address this, various approaches can be taken, depending on the requirements of the system. One option could be to use a REST API that has access to a replicated database system, where all state management is done through the API. Alternatively, a multi-data center cache, such as Redis, could be used to store and replicate state across different regions. In some cases, a distributed and replicated file system could also be used to store and manage state.
Overall, the choice of backend system and replication strategy will depend on the specific needs of the distributed system and the desired level of fault tolerance, consistency, and scalability. The flexibility and abstraction provided by the Context API make it possible to use a variety of backend systems and replication strategies, enabling teams to choose the approach that best meets their requirements.
Overall, the sample implementation provides a practical example of how the Context API can be used to simplify the management of state, telemetry, and feature flags in a distributed system, while promoting flexibility, scalability, and reliability.