In the rapidly evolving landscape of artificial intelligence, understanding the concepts of interpolation, extrapolation, and invention provides a useful framework for assessing the current capabilities of generative AI and envisioning its future trajectory. This progression from filling gaps in existing knowledge to creating truly novel ideas mirrors the development path of generative AI systems.
The Three Stages of Knowledge Extension

Interpolation is the process of estimating values within the boundaries of known data points. It's akin to filling in gaps between existing knowledge, like determining the temperature at 2:30 PM when you have readings from 2:00 PM and 3:00 PM. Interpolation operates within established patterns and tends to be highly reliable.
Extrapolation extends beyond the known data range. Rather than filling gaps, it projects existing patterns into uncharted territory. Think of weather forecasting that predicts conditions beyond recorded data or economic projections that extend current trends into the future. Extrapolation becomes increasingly uncertain the further it moves from established knowledge.
Invention represents a quantum leap beyond both interpolation and extrapolation. It's the creation of entirely new concepts, approaches, or solutions that don't simply extend existing patterns but introduce novel elements. Invention often requires creative insights that transcend the boundaries of established frameworks.
Generative AI: Current State and Future Horizons
Where Generative AI Stands Today: Masters of Interpolation
Today's generative AI models, including large language models (LLMs) like GPT-4, Claude, and Llama, excel primarily at interpolation. They've been trained on vast datasets of human-created content, allowing them to:
- Generate coherent text that mimics human writing styles and conventions
- Produce variations of existing imagery based on descriptive prompts
- Create code that follows established programming patterns and best practices
- Synthesize information across domains in ways that appear novel but are fundamentally recombinations of learned patterns
These systems operate within the statistical boundaries of their training data. They can fill in gaps remarkably well, making connections between concepts in ways that seem intelligent and occasionally insightful. However, their "creativity" is fundamentally interpolative—finding patterns within the space of what they've been shown rather than venturing into truly uncharted territory.
Example 1: Software Engineering Interpolation
Consider a software engineer working on implementing a user authentication system. They provide an AI with the following request:
"I need to implement a secure password reset flow in my Node.js application using Express and MongoDB."
The AI responds with a complete implementation including routes for requesting password resets, creating and validating reset tokens, and updating passwords securely. It includes email templates, security best practices like token expiration, and proper error handling.
This is classic interpolation. The AI hasn't invented a new authentication paradigm or security protocol. Instead, it's filling in the gaps between known concepts: password reset functionality, Express routing patterns, MongoDB operations, and established security practices. The AI combines these elements following standard industry patterns that existed in its training data. The result appears helpful and comprehensive but doesn't push beyond established approaches to authentication.
Example 2: E-commerce Business Interpolation
An entrepreneur asks an AI for help with a business idea:
"I want to start an e-commerce business selling sustainable home goods. What features should my website have?"
The AI generates a comprehensive list including:
- Product categorization by room and sustainability metrics
- Material sourcing transparency features
- Carbon footprint calculators for shipping
- Loyalty programs rewarding sustainable choices
- Subscription options for consumable products
- Educational content about sustainable living
This response demonstrates interpolation within the e-commerce domain. The AI combines established e-commerce best practices (categorization, loyalty programs) with sustainability concepts (transparency, carbon footprints) that already exist in its training data. The resulting suggestions are coherent and potentially valuable, but they don't introduce truly novel business models or website features that didn't exist before. The AI is connecting dots between existing concepts rather than creating entirely new ones.
Moving Toward Extrapolation: The Current Frontier
Generative AI is beginning to show signs of extrapolation capabilities, though these remain limited. Newer systems can:
- Make predictions about potential future events based on historical patterns
- Generate reasonable responses to scenarios they weren't explicitly trained on
- Combine concepts in ways that weren't present in their training data
- Propose solutions to novel problems by extending known principles
Example 1: Software Engineering Extrapolation
Building on our authentication system example, consider what happens when we push the AI further:
"How could I implement passwordless authentication that works even when users are offline for extended periods, while maintaining high security?"
Here, the AI begins to extrapolate beyond standard patterns. It might propose a system that:
- Uses locally stored encrypted biometric templates with periodic online verification
- Implements a progressive trust mechanism that adjusts access permissions based on time since last online verification
- Creates a blockchain-inspired local verification ledger that records authentication attempts for later server reconciliation
- Develops a time-bounded credential system with cryptographic degradation
This response represents extrapolation because it extends beyond common authentication patterns in the training data. The AI is projecting known security principles into a novel context (offline + passwordless) by combining elements of biometrics, zero-knowledge proofs, and distributed systems in ways that might not be explicitly documented in existing solutions. However, each component builds on known techniques rather than inventing fundamentally new security paradigms.
Example 2: E-commerce Extrapolation
For our sustainable e-commerce business, extrapolation occurs when the AI ventures beyond current common practices:
"How might e-commerce evolve in the next decade for sustainable products if AR/VR becomes mainstream and climate regulations tighten significantly?"
The AI might extrapolate:
- Virtual "sustainability spaces" where customers can visualize the environmental impact of products in their actual homes through AR
- Digital twin product passports that track real-time carbon footprints throughout the supply chain
- Predictive inventory systems that adjust stock based on forecasted environmental regulations
- Community-based micro-fulfillment centers that optimize for local sourcing
- Dynamic pricing that incorporates real-time environmental impact data
- Circular economy loops integrated directly into the purchase flow
This represents extrapolation because the AI is extending current e-commerce and sustainability trends into speculative future scenarios. It's projecting beyond what's commonly implemented today, combining emerging technologies with environmental trends to imagine plausible future developments. The ideas aren't documented in existing implementations but follow logically from current trajectories.
However, these extrapolations become less reliable the further the system moves from its training distribution. Ask an AI to imagine technologies 500 years in the future, and it will struggle to transcend the conceptual frameworks of the present. Its extrapolations often reflect human biases and limitations rather than truly novel possibilities.
The Invention Horizon: What's Needed for True Innovation
For generative AI to reach the invention stage—to create genuinely novel concepts rather than recombinations or extensions of existing ideas—several fundamental advances are required:
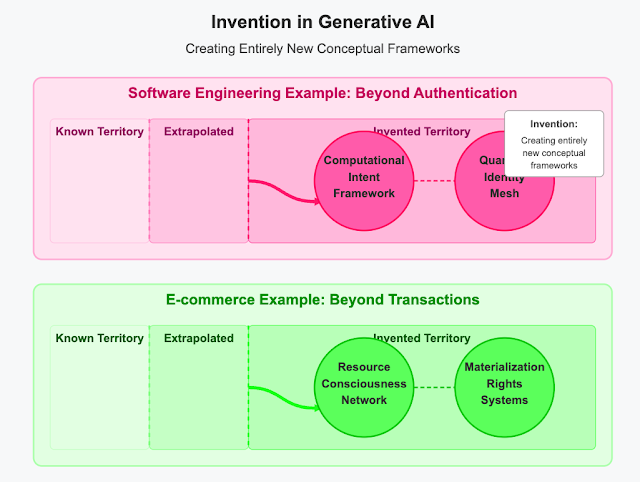
Example 1: Software Engineering Invention
True invention in software engineering would involve AI creating fundamentally new paradigms, not just novel combinations of existing approaches. Imagine an exchange with a truly inventive AI:
"Is there a completely different approach to application security that goes beyond current authentication models?"
A genuinely inventive AI might propose:
-
A "computational intent" framework that replaces traditional authentication entirely, where systems continuously verify the legitimacy of operations through a fundamentally new mathematical model of user behavior that makes credential theft conceptually impossible.
-
A "biological computing" security paradigm inspired by immune systems but operating on principles beyond current biometric approaches—creating self-evolving security boundaries that adapt based on environmental conditions in ways that cannot be predicted or reverse-engineered.
-
A "quantum identity mesh" that establishes a fundamentally new relationship between users and systems, where access is determined by properties that exist in neither the user nor the system but in the unique quantum relationship between them.
These examples represent invention because they establish entirely new frameworks rather than extending existing ones. They don't just fill gaps or project current trends—they redefine the problem space itself, creating new conceptual territories that weren't previously imagined.
Example 2: E-commerce Invention
For e-commerce, true invention would go beyond projecting current trends to completely reimagining commercial relationships:
"What might replace e-commerce entirely for sustainable products?"
A truly inventive AI might propose:
-
A "resource consciousness network" where products don't exist as discrete items to be purchased but as dynamic manifestations of community resource pools, fundamentally transforming ownership concepts into something neither capitalist nor communist but an entirely new economic paradigm.
-
A "regenerative exchange fabric" that dissolves the boundaries between producers and consumers, creating a non-transactional system of material flow based on principles that exist neither in market economies nor gift economies, operating on mathematical models of environmental harmony.
-
"Materialization rights" systems that replace purchasing with a fundamentally new relationship to physical goods, where objects come into being through principles that transcend both manufacturing and 3D printing, operating on new physical models of matter organization.
These concepts represent invention because they don't just improve or modify e-commerce—they posit entirely new frameworks that fundamentally reimagine how humans might relate to material goods.
For generative AI to reach this invention stage, several fundamental advances are required:
1. Causal Understanding
Current systems lack true causal models of the world. They identify correlations but don't understand the underlying mechanisms. Inventive AI will need to grasp not just what patterns exist but why they exist and how they might be transformed.
2. Self-Directed Exploration
Invention requires agency—the ability to set goals, pursue curiosity, and engage in open-ended exploration. Future AI systems will need to formulate their own questions and research agendas rather than simply responding to human prompts.
3. Conceptual Abstraction
Truly inventive systems must be able to create higher-level abstractions from concrete examples—essentially developing new frameworks for understanding rather than operating within existing ones. This requires meta-learning capabilities beyond today's architectures.
4. Embodied Experience
Many human inventions arise from physical interaction with the world. AI systems may need embodied experiences—whether through robotics or sophisticated simulations—to develop intuitions about physical reality that can lead to novel insights.
5. Cross-Domain Integration
Breakthrough inventions often occur at the intersection of disparate fields. Future AI will need deeper integration capabilities to identify non-obvious connections between domains and synthesize truly original concepts.
The Path Forward
The evolution from interpolation to invention won't follow a linear progression. We're already seeing nascent signs of inventive capabilities in certain narrow domains. For instance, AI systems have:
- Discovered potential new antibiotics by exploring chemical spaces in ways humans hadn't considered
- Proposed novel protein structures with specific functions
- Generated unexpected strategies in games like Go and chess
However, these represent early glimmers rather than general inventive capability. The journey will likely involve:
- Enhanced Training Paradigms: Moving beyond pure prediction to include causal reasoning, counterfactual thinking, and abductive inference
- Multimodal Integration: Combining language, vision, sound, and possibly other sensory inputs to develop richer conceptual models
- Interactive Learning Environments: Creating spaces where AI can experiment, fail, and learn from outcomes
- Human-AI Collaboration: Developing systems that can participate in iterative creative processes with human partners
- Metacognitive Capabilities: Building systems that can reflect on their own knowledge and reasoning processes
Conclusion
Generative AI currently excels at interpolation—filling gaps within the boundaries of human knowledge—and is beginning to demonstrate limited extrapolation capabilities. True invention, however, remains largely beyond its reach.
The progression from interpolation to invention mirrors the broader evolution of artificial intelligence from narrow, task-specific systems toward more general capabilities. Each stage brings both new possibilities and new challenges, requiring not just more data or compute but fundamentally new approaches to how AI systems learn and reason.
As researchers and developers work toward inventive AI, they must grapple with profound questions about the nature of creativity, the relationship between knowledge and innovation, and ultimately, what it means to generate truly original ideas. The answers will shape not just the future of AI but potentially the future of human knowledge itself.