Every time a developer asks an AI coding assistant to generate code, they're initiating a search process. But the question isn't whether search happens—it's where and how that search occurs. Search can be done in model knowledge base or it can use some tools to perform search.
Code Is Different - but why ?
Searching for code is interesting search problem and it has it unique challenges.
When a human programmer approaches a codebase, they don't just look for similar examples. They build a mental model of how the system works: - How data flows through the application - What architectural patterns are being used - How different modules interact and depend on each other - What the implicit contracts and assumptions are This mental model is what enables programmers to make changes without breaking the system, debug complex issues, and extend functionality in coherent ways.What are options for code search algorithms
Retrieval Augmentation Generation (RAG)

RAG excels at finding relevant information and synthesizing it into coherent responses. This works brilliantly for answering questions about historical facts or summarizing documents. But code isn't documentation—it's a living system of interconnected logic that demands deep understanding.
- The Precision Problem: When "Close Enough" Breaks Everything
The Context Catastrophe
- The Dynamic System Challenge
Perhaps most critically, effective coding requires real-time interaction with living systems. Coding is fundamentally about: - Writing code and seeing how it behaves - Running tests to validate assumptions - Using compiler errors as feedback - Debugging by tracing execution paths - Iterating based on runtime behavior RAG provides static information about how someone else solved a similar problem. But what you need is dynamic interaction with your current, specific codebase.Reasoning Retrieval Generation (RRG)

- Build Mental Models in Real-Time
Instead of retrieving similar code, reasoning-based agents analyze the actual codebase to understand: - How the system is structured and why - What patterns and conventions are being followed - How data flows through different components - What the implicit contracts and assumptions are- Leverage Tool Integration
Rather than retrieving documentation, effective coding agents interact directly with development tools: - Compilers and interpreters for immediate feedback - Testing frameworks to validate solutions - Debuggers to trace execution and find issues - Static analysis tools to understand code structure - Version control systems to understand change history- Think Through Problems Step-by-Step
Chain of thought reasoning allows agents to: - Trace through code execution paths to understand behavior - Identify root causes of bugs through logical deduction - Reason about the implications of changes before making them - Build solutions from first principles rather than pattern matchingTrade-Off - Aspect that you can't ignore
Knowledge Boundaries
RRG agents are limited by their training data. They can't access: - Documentation for recently released libraries - Community solutions to novel problems - Project-specific conventions not captured in code - Specialized domain knowledge from external sources But here's the key insight:Context Window Constraints
Without retrieval, agents must work within their context limits. Large codebases can exceed what fits in memory. However, this constraint forces better architectural approaches: - Focus on understanding system structure and patterns - Use tool integration to navigate codebases systematically - Build summarization and abstraction capabilities - Develop better code analysis and navigation strategiesSpecialized Domain Gaps
RRG agents may struggle with highly specialized domains not well-represented in training data. But this is where tool integration shines—rather than retrieving domain knowledge, agents can interact with domain-specific tools and APIs directly.Cost and Resources Challenges
What is solution - best of both world


Mental Model Filtering Process
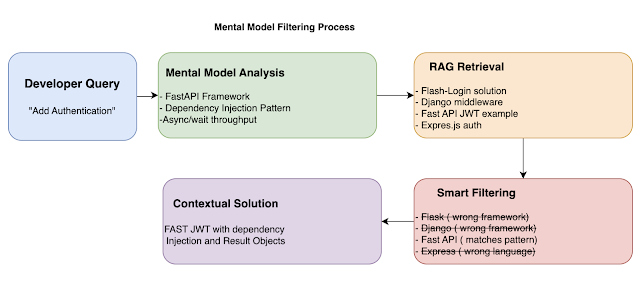

The battle for dominance in the coding agent landscape is heating up. Will the winner be IDE-integrated solutions like Cursor, Windsurf, VS Code, or IntelliJ? Perhaps it will be Claude Code or Openai-codex or google jules ? Or could the no-code and low-code platforms like Bolt, Loveable, Replit or Open source like Aider, or Cline ultimately ?
But here's the twist: while these coding agents compete fiercely for market share, someone else is already winning this game—and the answer might be more obvious than you think.
No comments:
Post a Comment