Java has wonderful feature that allow to inspect any object at run time and extract useful information about it for e.g constructor, methods, fields etc.
Reflection provides flexibility at run time to make decision without writing IF/ELSE, SWITH-CASE, it is used extensively in java and there are lot of framework developed based on it for eg ORM, Rule engine etc
We have to trade off performance for the cost of flexibility that reflections give to us specially if you execute any method via reflection, lets try to measure cost and see what can be done to improve it.
Simple Value Object
Take a simple class Order which has 2 property ( orderId,orderType)
public class Order {
private int orderId;
private String orderType;
public int getOrderId() {
return orderId;
}
public void setOrderId(int orderId) {
this.orderId = orderId;
}
public void setOrderType(String orderType) {
this.orderType = orderType;
}
public String getOrderType() {
return orderType;
}
}
Method Invocation
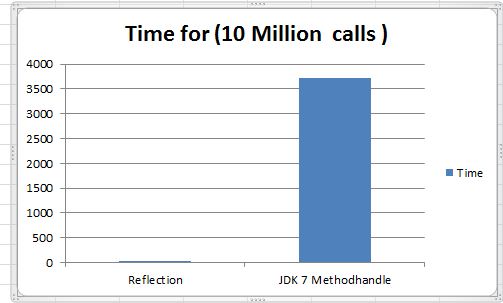
getOrderId function is called 10 Million time in loop and reflection is around 17X times slow for this test
That is very high cost paid for flexibility!
So what can be done, JDK 1.7 added more feature related to reflection. It is suppose to make life easy for developer by moving lot of plumbing code to java API.
MethodHandles class is supposed to do all the magic related to reflection use case, Lets try to measure it for our simple case.
Wow it is very very slow 106X times slow compared reflection, i don't want to compare with with normal method call. MethodHandles gives good abstraction for reflection, but on performance side it is very slow, so i am sure you want to re think before you use it.
What are the other options
What are the options to make it fast
- Go back to normal method call by writing big IF-ELSEIF-ELSE for each method
- Use some native call to perform reflection.
First option looks such a naive thing, you don't want to write all that and if your class has lot of function then it become nightmare to maintain it. There are some byte code manipulation API that we can use to generate such class. There are couple of options
ASM,
javassist for that.
May java developer don't want to use
second option because you want to stay away from native code due to portability issue, but it is worth trying it to see what type of performance we get. java has Unsafe class which is used internally by java for many things, i will also try to use this to find alternate ways of reflection.
Below is the chart for call of getOrderType 10 Million times
Wow this is some thing, using compiled class ( via javaassit) & Unsafe we can come close to normal method call. I will remove JDK 7 from graph, so that we have some proper scale in graph.
Now it is better, Unsafe is almost same as Normal method. Compiled is better than reflection, it amount 1.8X times faster than reflection.
There are some options to improve performance of "Compiled" class, the current implementation has below code
if("getOrderType".equals(s))
return (String)((com.atomic.RefTest.Order)obj).getOrderType();
if("getOrderId".equals(s))
return Integer.valueOf(((com.atomic.RefTest.Order)obj).getOrderId());
There are if condition for making decision which method to call, if we can remove that we might get some performance improvement, so now it will look like
((com.atomic.ReflectionTest.Order)obj).getOrderType();
Below is graph with that change - CompiledSingleProp is one with no IF condition
Performance of CompiledSingleProp is similar to Unsafe and close to Normal function call.
So we can definitely use "Option 1" for reflection without significant performance impact on application.
Performance compare Object vs primitive property
While doing this test i notice performance of primitive property is slow as compared to object property and reason is because we have to create Wrapper class to represent primitive type and it adds overhead.
Below is graph for comparing primitive vs object property
Compiled class performs better in case of object and it is slow for primitive type(int/float/long), but Unsafe performance has not effect on type of property, so based on use case proper alternate solution can be used to get best performance.
Conclusion
There are many alternate of reflection available, this post talks about few. Compiled class & Unsafe are the most efficient way to perform property get/set calls. These options should be consider if your application is using reflections heavily. Lot of professional tools uses's compiled property.
About Sample Code
For unsafe i am not generating any code, it can easily done using logic similar to PropertyGenerator
Java Reflection Example

{kind=link}